オープンソースの運用管理ツール「Hinemos」にはSNMPクライアント機能が搭載されており、サーバーのCPUやI/Oといったリソースの利用状況を監視できる。今回はHinemos 4.0を使い、サーバーのリソースを監視する方法、そして監視対象が閾値を超えた場合に通知を行う方法について解説する。 前記事ではHinemosを使い、pingやHTTP、SQL文の発行などによるサーバーの死活監視を行う方法を解説した。いっぽう、このような「ポーリング型」の死活監視だけでなく、マシンのCPUやディスクI/O、ネットワークI/O、ディスクの利用状況といったリソースを監視したいという場合もあるだろう。この目的に利用できるのが、HinemosマネージャのSNMPマネージャ機能だ。 SNMP(Simple Network Management Protocol)は、ネットワーク経由でネットワーク機器などの情報や制御コマンドをやり取りするためのプロトコルである。SNMPによるモニタリングや制御は企業向けルーターなどネットワーク機器の管理によく使われているが、サーバーに関してもSNMPエージェントと呼ばれるソフトウェアをインストールすることで監視できる。本記事では監視対象とするサーバーにSNMPエージェントを導入し、Hinemosからリソース情報を監視する方法について解説する。 UNIX/Linux環境において広く使われているSNMPエージェントに、「Net-SNMP」がある。Net-SNMPはオープンソースで開発されているSNMPエージェントおよび関連ツール実装で、さまざまな環境で動作する。Red Hat Enterprise Linux(やその互換OSであるCentOSなど)では公式パッケージが提供されており、yumコマンドでインストールが可能だ。
# yum install net-snmp
なおnet-snmpパッケージにはエージェント関連のコンポーネントしか含まれていない。動作確認に利用するための関連ツールなどは別途net-snmp-utilsパッケージに含まれているので、こちらもインストールしておく。
# yum install net-snmp-utils
SNMPエージェントの設定は、/etc/snmp/snmpd.confファイルに記述されている。このファイルは400行近くあるが、その多くは設定項目を解説したコメント行なので、実際に設定する個所は多くない。 このファイルでまず設定が必要なのは、アクセス制御に関する部分だ(リスト1)。追加した個所は太字で示している。 リスト1 /etc/snmp/snmpd.confの変更個所(アクセス制御関連)
# —————————————————————————- # Here is a commented out example configuration that allows less # YOU SHOULD CHANGE THE “COMMUNITY” TOKEN BELOW TO A NEW KEYWORD ONLY ## sec.name source community ## group.name sec.model sec.name ## incl/excl subtree mask ## -or just the mib2 tree- #view mib2 included .iso.org.dod.internet.mgmt.mib-2 fc ## context sec.model sec.level prefix read write notif ここではまず、「com2sec」行で「セキュリティ名」を定義している。
com2sec local localhost SfJPMag セキュリティ名はアクセス・権限制御を行うための設定名だ。ここではlocalhostからの接続を「local」というセキュリティ名で、192.168.100.0/24からの接続を「mynetwork」というセキュリティ名で参照するよう指定している。それぞれの行の最後にある文字列(ここでは「SfJPMag」)は「コミュニティ名」と呼ばれる文字列で、SNMPではこのコミュニティ名を用いて認証を行う。そのため、コミュニティ名は外部から推測できないものを指定するのが好ましい。ここでは例として「SfJPMag」と指定しているが、実際に設定を行う場合は別の適切な文字列に置き換えてほしい。 次に、「group」行でグループを定義する。グループは1つ以上のセキュリティ名をまとめたもので、アクセス制御はこのグループ単位で行われる。ここでは「MyROGroup」というグループに先ほど作成したmynetworkを所属させるよう設定している。なお、グループを定義する際はセキュリティ名とともにSNMPの「セキュリティモデル」を指定する必要があるが、ここではすべてのセキュリティモデルを許可する「any」を指定している。
group MyROGroup any mynetwork
「view」行ではSNMPで取得できる情報の範囲(ビュー)を定義できる。具体的な指定方法についてはドキュメントを参照していただくとして、ここではすべてのデータにアクセスできる「all」というビューを定義している。
view all included .1 80
最後に「access」行でグループごとにビューを指定する。ここではMyROGroupに対し、allというビューで指定された情報を認証無しでアクセスできるよう設定している。
access MyROGroup “” any noauth 0 all none none
このように設定することで、192.168.100.0/24の範囲のIPアドレスから、「SfJPMag」というコミュニティ名でアクセスすることで、ホストに関するすべての情報を取得できるようになる。 続いて、ディスクの使用量についてSNMPで取得できるよう設定しておこう。これは、設定ファイル内でコメントアウトされている「disk」行を有効にするだけで良い。 リスト2 /etc/snmp/snmpd.confの変更個所(ディスク関連)
############################################################################### # The agent can check the amount of available disk space, and make # disk PATH [MIN=100000] # Check the / partition and make sure it contains at least 10 megs. #disk / 10000 # —————————————————————————-
以上の設定が完了したら、SNMPエージェントであるsnmpdを起動(もしくは再起動)する。
起動する場合 また、ファイアウォールの設定も行っておく。SNMPでは下記のポートおよびプロトコルを使用する。
使用するポート番号:160および161 外部からSNMPエージェントにアクセスを行うため、これらのポートおよびプロトコルを利用できるようファイアウォールの設定を行っておこう。 SNMPエージェントの設定が完了したら、続いて動作確認を行っておく。動作確認にはnet-snmp-utilsパッケージに含まれるsnmpwalkコマンドを使用する。まず、システム情報を取得できるかどうかを確認するため、以下のようにsnmpwalkコマンドを実行してみよう。
$ snmpwalk -v 1 <ホストのIPアドレス> -c <指定したコミュニティ名> system
正しくSNMPエージェントが動作している場合、次のようにホストに関する情報などが含まれる出力が得られる。
SNMPv2-MIB::sysDescr.0 = STRING: Linux sata 2.6.32-279.5.2.el6.x86_64 #1 SMP Fri Aug 24 01:07:11 UTC 2012 x86_64 また、次のコマンドを実行してディスクの使用状況を取得できているかどうかも確認してみよう。
$ snmpwalk -v 1 <ホストのIPアドレス> -c <指定したコミュニティ名> disk
正しく設定が行われていれば、次のようにディスクに関する情報が出力される。
$ snmpwalk -v 1 sata -c SlashSfJP disk 以上で監視対象側での設定は完了だ。続いてHinemosマネージャ側でSNMPを使ったリソース監視を行うための設定を行っていく。 SNMPで監視を行う場合、まず監視対象とするノードのSNMPエージェントにアクセスするためのコミュニティ名などを登録しておく必要がある。この設定はHinemosの「リポジトリ」パースペクティブで行える。「リポジトリ[ノード]」ビューで設定したいノードを指定し、登録方法で「ノード単位」を選択してIPアドレスおよびコミュニティ名を入力して「Find」をクリックすると、コミュニティ名の登録とSNMPエージェントへの問い合わせが行われ、自動的に各種情報が取得される(図1)。 この作業は、SNMPによる監視を行いたいマシンすべてに対し実行しておく必要がある。SNMPによる情報取得は既存のノードだけでなくノードを新規に追加する際にも利用できるので、監視対象とするサーバーではあらかじめSNMPエージェントを動作させておくと良いだろう。 HinemosではSNMPを使った監視として、「SNMP監視」と「SNMPTRAP監視」、「プロセス監視」、「リソース監視」という項目が用意されているが、このなかでCPUの利用状況などを監視するためのものが「リソース監視」だ。監視できるリソースの種別はリスト1のとおりで、非常に多くの情報を監視できることが分かる。 リスト1 リソース監視機能で監視できるリソース
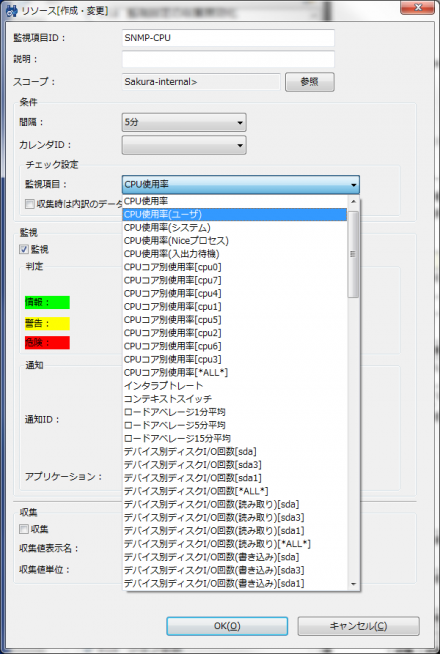
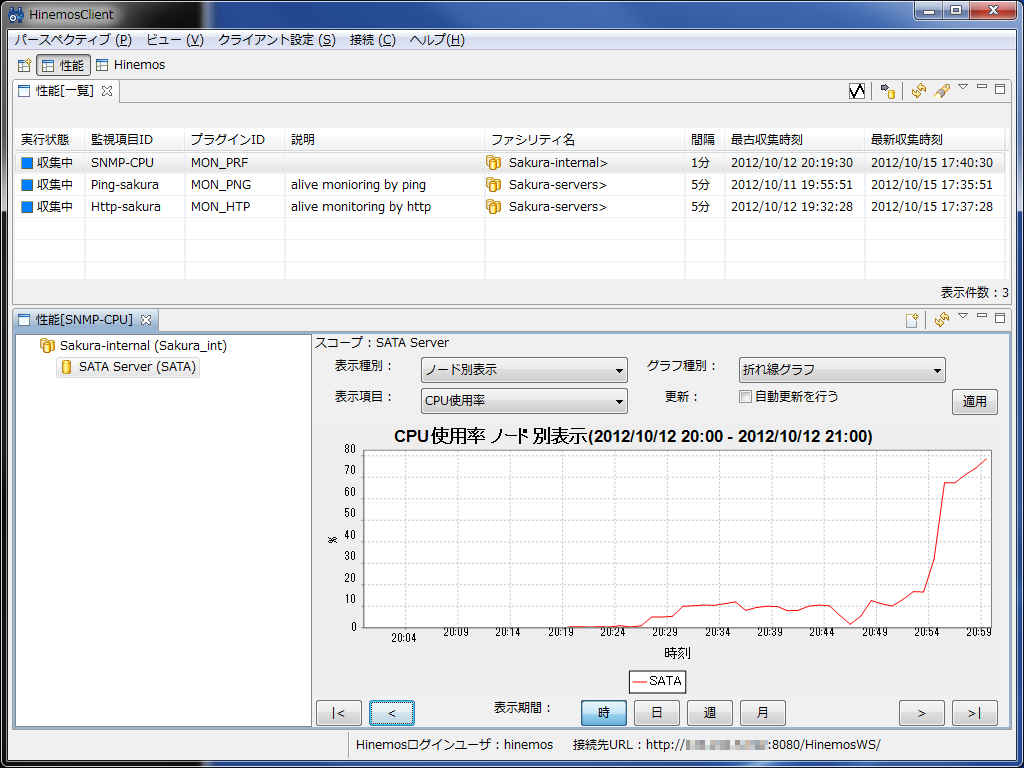
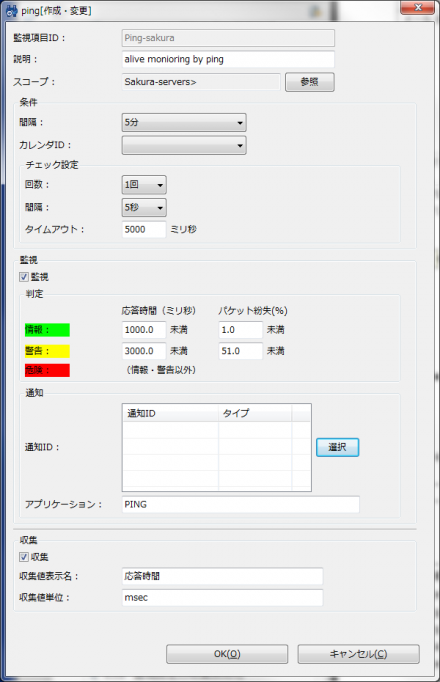
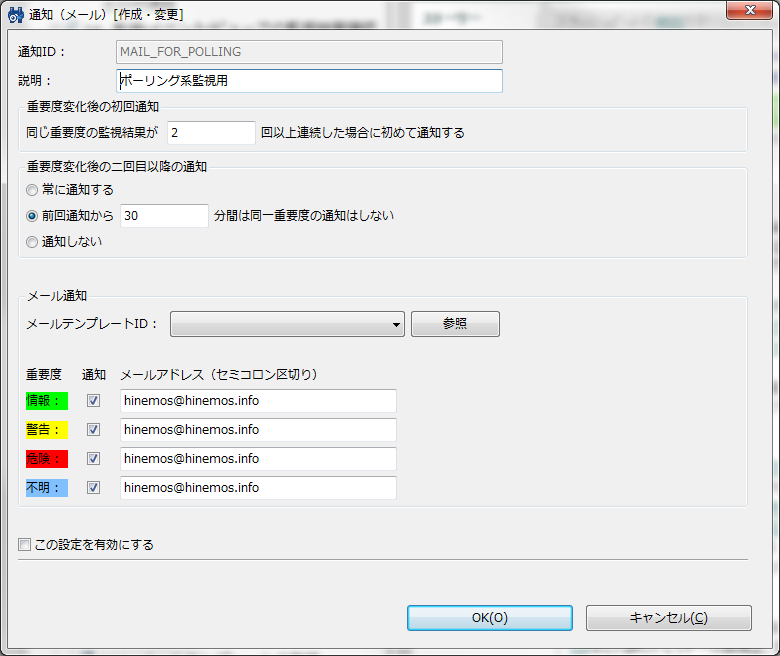
CPU使用率(ユーザ) リソース監視を行うには、「監視設定」パースペクティブを開き、「監視設定[一覧]」ビューのツールバー内にある「+」(作成)ボタンをクリックして監視設定を作成する(図2)。 監視種別を選択する画面が表示されるので、ここでは「リソース監視(数値)」を選択する(図3)。 「リソース[作成・変更]」画面が表示されるので、ほかの監視設定と同様、「監視項目ID」や「スコープ」、取得間隔などを入力していく(図4)。 監視するリソースの種類は、「監視項目」リストボックスで選択する。ここではCPU使用率やディスクI/O、メモリ使用率などが選択できる(図5)。 あとは通知関連の設定を行い、また「収集」にチェックを入れて「OK」をクリックすれば良い。 収集した情報については、「性能」パースペクティブで閲覧できる。「性能[一覧]」ビューに監視項目一覧が表示されるので、確認したい監視項目を選択してツールバーの「グラフ追加」(折れ線グラフのアイコン)をクリックすると画面下側にグラフが表示される(図6)。 HinemosではpingやHTTP、SQL、SNMPなど、さまざまな監視機能を備えている。そして、これらの監視結果がある一定値を超えた場合にユーザーに対して通知を行う機能も備えられている。これにより、なんらかの異常が発生した場合に管理者がより迅速にそれを知ることが可能になる。以下では、このような通知機能を利用する設定に設定について解説していこう。Hinemosでは通知を発生させる条件や通知方法を「通知」という単位で管理している。用意されている通知方法は「ステータス通知」や「メール通知」など6種類だ(表1)。 Hinemosでは通知設定と監視設定が独立したものとなっており、まず通知設定で通知の表示方法などを指定し、続いて監視設定で使用する通知設定を指定する、という流れとなる。 今回はステータス通知およびイベント通知、メール通知について説明しよう。まずステータス通知およびイベント通知だが、これらは通知発生時に「監視」パースペクティブ内の「監視[ステータス]」および「監視[イベント]」ビューにその旨を表示させるというものだ。たとえば図7は、ping監視の結果がある一定値を超えた場合に「情報」もしくは「危険」という通知を発生させ、「情報」という通知についてはステータス通知で、「危険」という通知についてはステータス通知およびイベント通知で出力された例となる。 ステータス通知とイベント通知の違いだが、ステータス通知についてはそれぞれの監視項目ごとに最新の結果しか表示されず、同じ監視項目からより新しい通知が発生した場合表示が上書きされるのに対し、イベント通知は明示的に削除しない限りリストに表示され続ける。ステータス通知は監視対象の最新状況を把握するためのもので、イベント通知は監視対象で発生した問題をログとして記録するためのものと考えれば良いだろう。 Hinemosではデフォルトでいくつかの通知設定があらかじめ用意されており、これらは監視設定パースペクティブの「監視設定[通知]」ビューで確認できる。既存の通知を編集するには、編集したい通知を選択してツールバーの「編集」をクリックする(図8)。 たとえば通知ID「EVENT_FOR_POLLING」は、ping監視などのポーリング型監視向けの通知設定だ(図9)。 ここでは、監視項目ごとに通知を発生させる条件を指定できる。たとえば「EVENT_FOR_POLLING」通知設定のデフォルトではすべての重要度のイベントについて、監視結果の重要度が変化後2回以上同じ重要度となった場合に通知を行うように設定されている。 監視結果に応じた通知を行うには、通知ごとの設定を行った後、監視項目ごとの設定画面で「監視」を有効にし、さらにその通知IDを登録しておく必要がある(図10)。 監視項目ごとの設定画面を開き、「通知」枠内の「選択」をクリックすると、通知一覧が表示される(図11)。ここで使用したい通知にチェックを入れ、「OK」をクリックする。 たとえば図11のように指定した場合、指定した監視結果の重要度に応じて「EVENT_FOR_POLLING」通知と「MAIL_FOR_POLLING」通知、「STATUS_FOR_POLLING」通知が行われる。 メール通知の場合も、基本的な設定方法はイベント通知やステータス通知と同じだ。たとえばpingの値が一定以上となった場合にメールで通知を送るという設定を行いたい場合、デフォルトで用意されているメール通知設定(通知ID「MAIL_FOR_POLLING」)をカスタマイズして使用すれば良い(図12)。 メール通知設定についても、設定項目はイベント通知やステータス通知とほぼ同じだ。メール通知で異なるのは、重要度ごとに通知メールを送信するメールアドレスを設定できる点だ。また、デフォルト設定ではリスト2のようなメールが送信される設定となっている。 リスト2 通知メールの例
Subject: Hinemos通知(情報) 出力日時:2012/10/12 19:10:51 メールの文面は「メールテンプレート」機能を利用することでカスタマイズが可能だ。メールテンプレートについてはここでは解説しないので、詳しくはドキュメントを参照してほしい。 SNMPによる監視ではさまざまなリソースを監視できる。サーバー監視に必要なほぼすべての情報を確認できるといっても過言ではない。ここではリソースの変化をグラフで表示するところまでを説明したが、監視機能と組み合わせることで、リソースの消費が一定条件を超えた際にイベントとしてそれを記録したり、メールで通知を行うこともできる。環境によって取得すべき項目などは変わってくるが、HinemosとSNMPの組み合わせを使えばほとんどのケースでは十分に対応できるのではないだろうか。各自の環境に応じた監視設定を試していただきたい。HinemosをSNMPクライアントとして使用する
SNMPエージェントのインストール
SNMPエージェントの設定
# restrictive access.
# KNOWN AT YOUR SITE. YOU *MUST* CHANGE THE NETWORK TOKEN BELOW TO
# SOMETHING REFLECTING YOUR LOCAL NETWORK ADDRESS SPACE.
#com2sec local localhost COMMUNITY
#com2sec mynetwork NETWORK/24 COMMUNITY
com2sec local localhost SfJPMag
com2sec mynetwork 192.168.100.0/24 SfJPMag
#group MyRWGroup any local
#group MyROGroup any mynetwork
#
#group MyRWGroup any otherv3user
#…
group MyROGroup any mynetwork
#view all included .1 80
view all included .1 80
#access MyROGroup “” any noauth 0 all none none
#access MyRWGroup “” any noauth 0 all all all
access MyROGroup “” any noauth 0 all none none
com2sec mynetwork 192.168.100.0/24 SfJPMag
# disk checks
#
# sure it is above a set limit.
#
# PATH: mount path to the disk in question.
# MIN: Disks with space below this value will have the Mib’s errorFlag set.
# Default value = 100000.
disk / 10000
# service snmpd start
再起動する場合
# service snmpd restart
使用するプロトコル:udp
SNMPエージェントが正しく動作しているかどうかをチェックする
SNMPv2-MIB::sysObjectID.0 = OID: NET-SNMP-MIB::netSnmpAgentOIDs.10
DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (33894843) 3 days, 22:09:08.43
SNMPv2-MIB::sysContact.0 = STRING: Root <root@localhost> (configure /etc/snmp/snmp.local.conf)
SNMPv2-MIB::sysName.0 = STRING: sata
SNMPv2-MIB::sysLocation.0 = STRING: Unknown (edit /etc/snmp/snmpd.conf)
:
:
UCD-DISKIO-MIB::diskIOIndex.1 = INTEGER: 1
UCD-DISKIO-MIB::diskIOIndex.2 = INTEGER: 2
UCD-DISKIO-MIB::diskIOIndex.3 = INTEGER: 3
UCD-DISKIO-MIB::diskIOIndex.4 = INTEGER: 4
UCD-DISKIO-MIB::diskIOIndex.5 = INTEGER: 5
UCD-DISKIO-MIB::diskIOIndex.6 = INTEGER: 6
UCD-DISKIO-MIB::diskIOIndex.7 = INTEGER: 7
:
:
HinemosのSNMPマネージャ機能を使う
コミュニティ名を登録する
![図1 「リポジトリ[ノードの作成・変更]」画面](../../knowledge-sub/wp/wp-content/uploads/2013/06/010_snmp08.png)
監視設定を行う
CPU使用率(システム)
CPU使用率(Niceプロセス)
CPU使用率(入出力待機)
デバイス別ディスクI/O回数(読み取り)
デバイス別ディスクI/O回数(書き込み)
デバイス別ディスクI/O量デバイス別ディスクI/O量(読み取り)
デバイス別ディスクI/O量(書き込み)
メモリ使用率(スワップ)
メモリ使用率(実メモリ)
実メモリ中のメモリ使用率(ユーザ)
実メモリ中のメモリ使用率(バッファ)
実メモリ中のメモリ使用率(キャッシュ)
スワップI/O(イン)
スワップI/O(アウト)
スワップブロック数(イン)
スワップI/O(アウト)
パケット数合計(受信)
パケット数合計(送信)
デバイス別パケット数(受信)
デバイス別パケット数(送信)
エラーパケット数合計(受信)
エラーパケット数合計(送信)
デバイス別エラーパケット数(受信)
デバイス別エラーパケット数(送信)
ネットワーク情報量(受信)
ネットワーク情報量(送信)
デバイス別ネットワーク情報量(受信)
デバイス別ネットワーク情報量(送信)
![図4 「リソース[作成・変更]」画面](../../knowledge-sub/wp/wp-content/uploads/2013/06/040_snmp05-440x654.png)
監視結果に応じて通知を行う
通知方法
説明
ステータス通知
Hinemosクライアントの「監視」パースペクティブ内「管理[ステータス]ビューに通知を表示する
イベント通知
Hinemosクライアントの「監視」パースペクティブ内「管理[イベント]ビューに通知を表示する
メール通知
あらかじめ指定しておいたメールアドレス宛にメールで通知を行う
ジョブ通知
通知の発生時、あらかじめ指定しておいた特定のジョブを実行する
ログエスカレーション通知
syslog形式のログで通知を行う
コマンド通知
通知の発生時、あらかじめ指定しておいた特定のコマンドを実行する
![図8 監視設定パースペクティブの「監視設定[通知]」ビュー](../../knowledge-sub/wp/wp-content/uploads/2013/06/200_mail01.png)
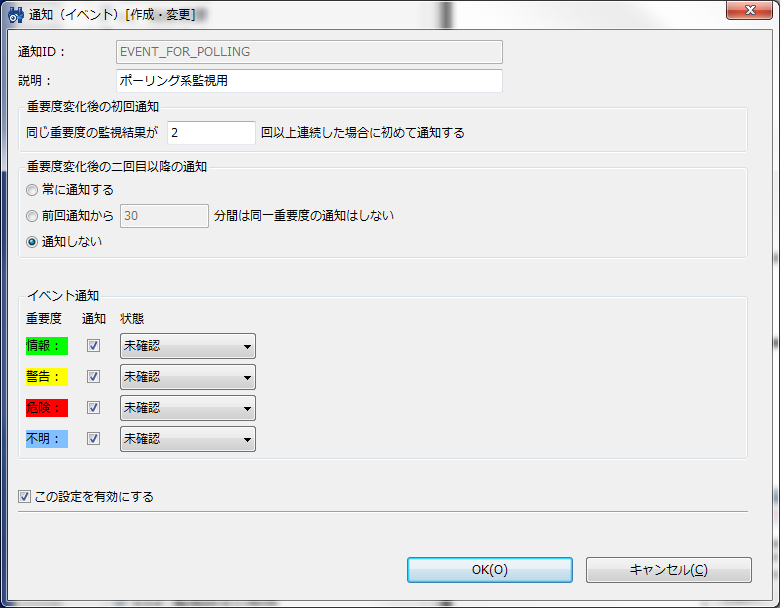
監視項目ごとに利用する通知を設定する
![図11 「通知[一覧]」画面で使用する通知にチェックを入れる](../../knowledge-sub/wp/wp-content/uploads/2013/06/240_mail08.png)
アプリケーション:PING
重要度:情報
メッセージ:PING [2012/10/12 19:10:51] Pinging 133.242.5.192 (133.242.5.192) .\xA\xA\xAPing statistics for 133.242.5.192:\xAPackets: Sent = 1, Received = 1, Lost = 0 (0% loss),Approximate round trip times in milli-seconds:\xA\x9Minimum = 0.05ms, Maximum = 0.05ms, Average = 0.05ms\xA
スコープ:Sakura-servers
さまざまに応用できるSNMP監視
おしらせ

技術系ナレッジ
運用管理ツール「Hinemos」によるリソース監視と通知設定
この記事の筆者
バックナンバー
- エージェントレスでシンプルな構成管理ツール「Ansible」入門
- コンテナ管理ツール「Panamax」をCoreOSと組み合わせて使ってみよう
- GitHubのようなサイトを独自に運用できる「GitLab」や「GitBucket」を使ってみよう
- Zabbixで作るサーバー監視環境(Zabbix 2.4対応版)
- 15分で作る、Logstash+Elasticsearchによるログ収集・解析環境
- 「Serverspec」を使ってサーバー環境を自動テストしよう
- KVM用仮想マシンをVagrantで手軽に作る
- Vagrantで作った仮想マシンを簡単に共有できる「Vagrant Share」を使ってみる
- Packerを使ったISOイメージからの仮想マシン自動デプロイ
- 「Packer」でDocker用のイメージファイルを作ってみよう
- Docker向けのコンテナをゼロから作ってみよう
- Dockerコンテナをクラウドサービス上で共有できる「Docker Hub」を使ってみる
- LXCを使った権限分離とテンプレートのカスタマイズ
- 15分で分かるLXC(Linux Containers)の仕組みと基本的な使い方
- さくらのクラウド APIをRubyから操作する
- さくらのクラウドAPIを使ってみよう(1)——コマンドラインツール「sacloud」から使う
- さくらの専用サーバを「さくらのクラウド」と組み合わせて使う――はじめての「さくらの専用サーバ」(5)
- SSDやioDriveといった高速ストレージの性能をチェック――はじめての「さくらの専用サーバ」(4)
- 専用サーバ上で複数のマシンをネットワーク接続する――はじめての「さくらの専用サーバ」(3)
- 仮想環境構築ツール「Vagrant」で開発環境を仮想マシン上に自動作成する
- リモートから専用サーバを操作する――はじめての「さくらの専用サーバ」(2)
- 柔軟なログ収集を可能にする「fluentd」入門
- 「さくらの専用サーバ」ってどういうサービス?――はじめての「さくらの専用サーバ」(1)
- サーバー設定ツール「Chef」応用編:knife-soloとData Bagを使う
- 独自Debパッケージやaptリポジトリを使ったサーバー管理術
- カスタムRPMや独自yumリポジトリではじめるソフトウェア管理術
- CPUやメモリなどのシステム性能を比較するベンチマークツール
- ネットワーク/ストレージの処理能力をチェックするためのベンチマークツール
- サーバー設定ツール「Chef」の概要と基礎的な使い方
- Puppetを使ったLinuxシステムの設定自動管理
- モニタリングツール「Cacti」でのリソース監視
- 統合監視ツール「Zabbix」によるサーバー監視
- 運用管理ツール「Hinemos」によるリソース監視と通知設定
- 運用管理ツール「Hinemos」によるサーバー死活監視
- 「skipfish」でWebアプリの脆弱性をチェックする
- Windowsでも使える脆弱性スキャナ「Nessus」を使う
- 脆弱性スキャナ「OpenVAS」でのセキュリティチェック
- 高機能なLinuxベースのソフトウェアルーター「Vyatta」を使う
- 「Linux Virtual Server」と「Keepalived」で作る冗長化ロードバランサ
- AWS互換APIや外部ツールでOpenStackを操作する
- OpenStack Swiftを使ってクラウドストレージサービスを構築する
- OpenStackの仮想ネットワーク管理機能「Quantum」の基本的な設定
- OpenStack 2012.2で追加された新機能「Cinder」を使う
- ポートスキャンツール「Nmap」を使ったセキュリティチェック



この記事についてコメントする